Preprocessing
The preprocessing module is used to pre- and post-process the data. Preprocessors are applied to the input data before it is passed to the model, and postprocessors are applied to the output data after it has been produced by the model and (in training) after the training loss has been calculated. The module contains the following classes:
- class anemoi.models.preprocessing.BasePreprocessor(config=None, data_indices: IndexCollection | None = None, statistics: dict | None = None)
Bases:
ModuleBase class for data pre- and post-processors.
- class anemoi.models.preprocessing.Processors(processors: list, inverse: bool = False)
Bases:
ModuleA collection of processors.
- class anemoi.models.preprocessing.StepwiseProcessors(lead_times: list[str])
Bases:
ModuleOrdered container for per-step processors that can include missing steps.
Normalizer
The normalizer module is used to normalize the data. The module contains the following classes:
- class anemoi.models.preprocessing.normalizer.InputNormalizer(config=None, data_indices: IndexCollection | None = None, statistics: dict | None = None)
Bases:
BasePreprocessorNormalizes input data with a configurable method.
- transform(x: Tensor, in_place: bool = True, data_index: Tensor | None = None) Tensor
Normalizes an input tensor x of shape […, nvars].
Normalization done in-place unless specified otherwise.
The default usecase either assume the full batch tensor or the full input tensor. A dataindex is based on the full data can be supplied to choose which variables to normalise.
- Parameters:
x (torch.Tensor) – Data to normalize
in_place (bool, optional) – Normalize in-place, by default True
data_index (Optional[torch.Tensor], optional) – Normalize only the specified indices, by default None
- Returns:
_description_
- Return type:
torch.Tensor
- inverse_transform(x: Tensor, in_place: bool = True, data_index: Tensor | None = None) Tensor
Denormalizes an input tensor x of shape […, nvars | nvars_pred].
Denormalization done in-place unless specified otherwise.
The default usecase either assume the full batch tensor or the full output tensor. A dataindex is based on the full data can be supplied to choose which variables to denormalise.
- Parameters:
x (torch.Tensor) – Data to denormalize
in_place (bool, optional) – Denormalize in-place, by default True
data_index (Optional[torch.Tensor], optional) – Denormalize only the specified indices, by default None
- Returns:
Denormalized data
- Return type:
torch.Tensor
Remapper
The remapper module is used to do in-place transformations of the data using a set of predefined transforms and their inverses. This process is crucial for variables with pathological distributions, such as variables with sharp peaks, long tails or other non-Gaussian shapes. It is especially important for diffusion models where the data distribution interacts with the noise distribution.
Note
The remapper module enables only single-variable transformations.
Multi-variable transformations (such as (ws wdir) -> (u v)) are
not supported for memory reasons and must be performed at the level
of the datasets.
The remapper module supports the following transformations:
none(no transformation)affine(x -> scale * x + shift)log1p(log(1+x))sqrtboxcox((x^lambd - 1) / lambd) or (log(x) if lambd == 0) wikipower(x^lambd)atanh(atanh(rho * (2x - 1)) / rho)asinh(asinh(x))displace_boundary_atoms(shifts precise boundary peaks away from other values to give the model a non-zero width bucket to model them)
Several remappers can be applied one after the other in a chain. The order of the remappers is important, as the output of one remapper is the input to the next remapper. Remappers must be applied after the normalizer as normalizer relies on the computed statistics of the dataset.
Example tranform functions:
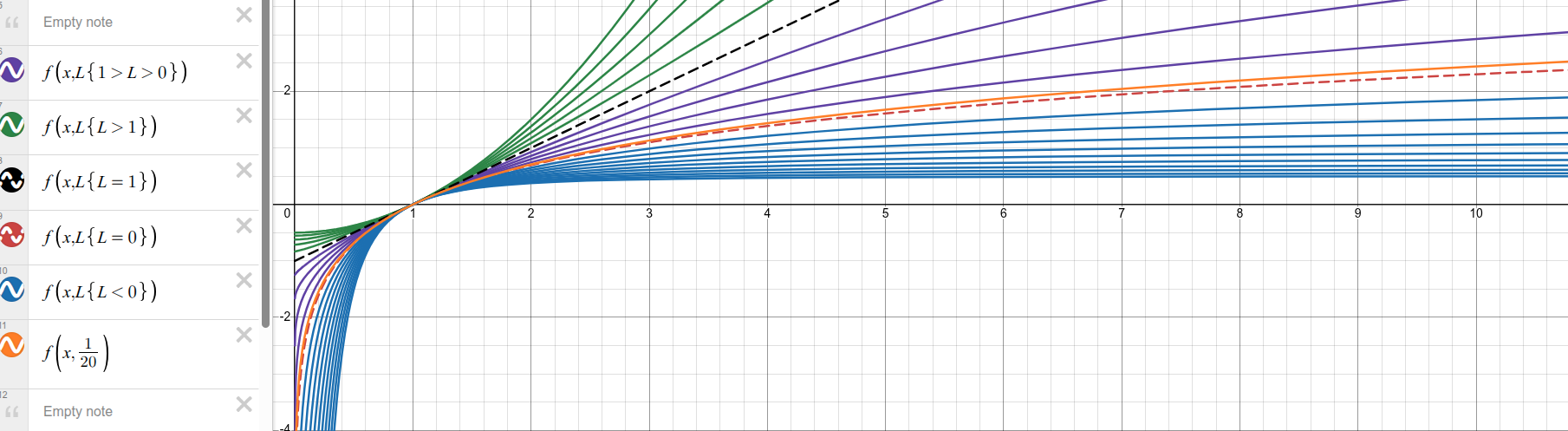
Box-cox remapper transform function examples with λ = [-2, -1.8, … , 2]. Negative λ is blue, λ=0 red, 0<λ<1 purple, λ=1=linear dashed black, and λ>1 green. Input Values must be positive.
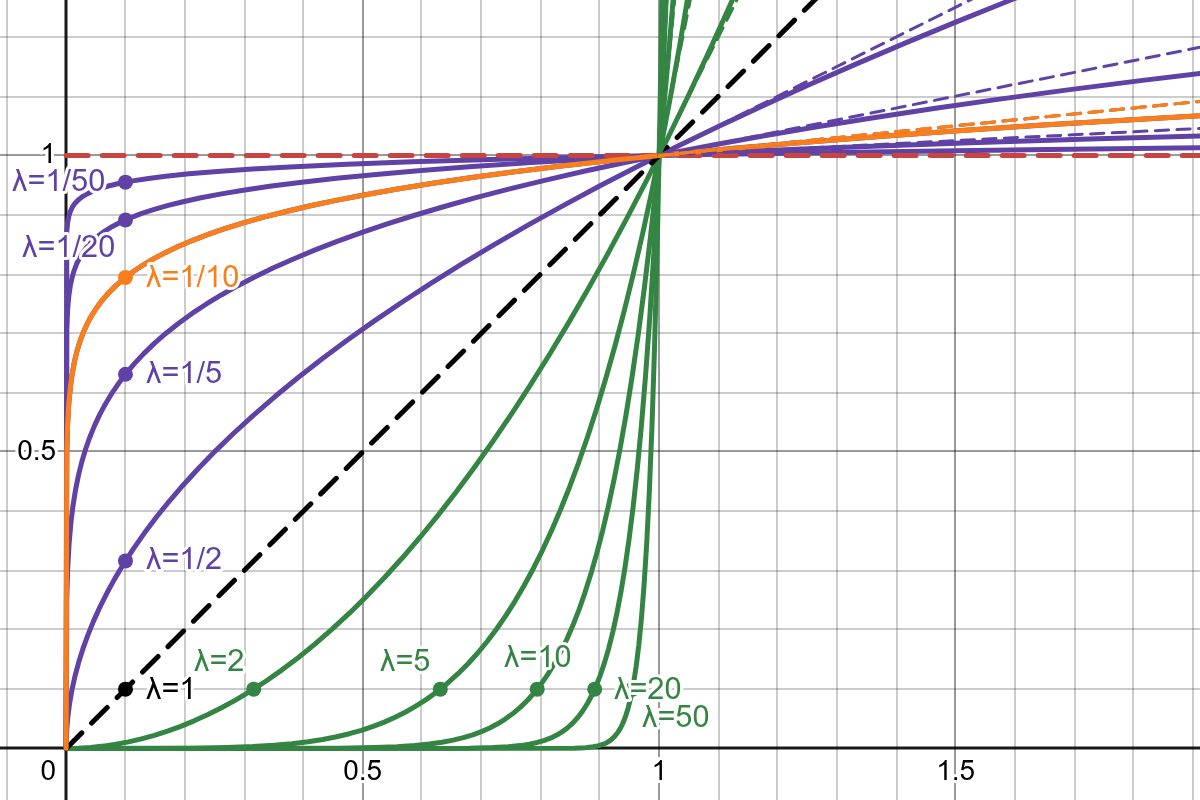
Power remapper transform function examples.
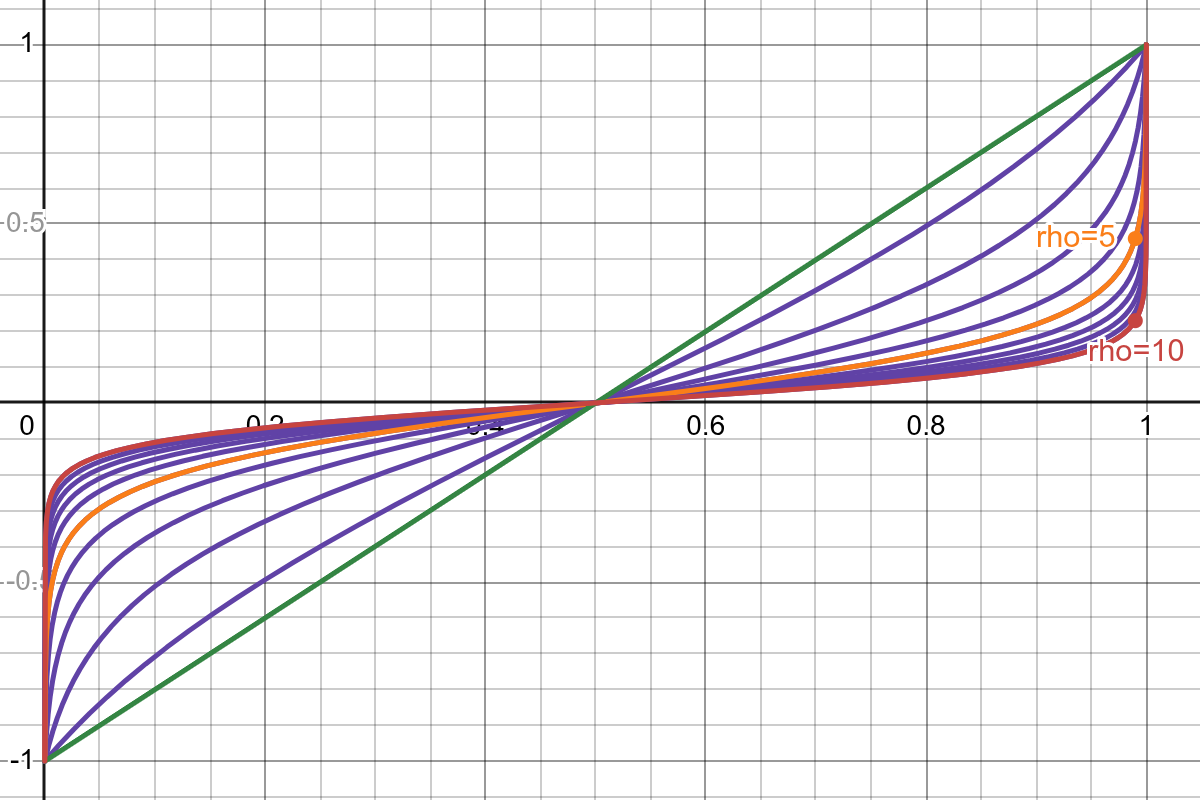
Atanh remapper transform function examples.
Example configuration:
data:
processors:
normalizer:
_target_: anemoi.models.preprocessing.normalizer.InputNormalizer
config:
default: "mean-std"
max: ["tp","tcc"]
remapper1:
_target_: anemoi.models.preprocessing.remapper.Remapper
config:
power: ["tp"]
atanh: ["tcc"]
method_kwargs:
power:
lambd: 0.1
tangent_linear_above_one: true
atanh:
rho: 3.0
remapper2:
_target_: anemoi.models.preprocessing.remapper.Remapper
config:
affine: ["tp"]
displace_boundary_atoms: ["tcc"]
method_kwargs:
affine:
scale: 2.0
displace_boundary_atoms:
lower_atom: -1.0
lower_target: -1.5
upper_atom: 1.0
upper_target: 1.5
eps: 1e-4
remapper3:
_target_: anemoi.models.preprocessing.remapper.Remapper
config:
displace_boundary_atoms: ["tp"]
method_kwargs:
displace_boundary_atoms:
lower_atom: 0
lower_target: -1
eps: 1e-7
The module contains the following classes and functions:
- class anemoi.models.preprocessing.remapper.Remapper(config=None, data_indices: IndexCollection | None = None, statistics: dict | None = None)
Bases:
BasePreprocessorRemap and convert variables for single variables.
- anemoi.models.preprocessing.mappings.noop(x)
No operation.
- anemoi.models.preprocessing.mappings.affine_transform(x, scale=1.0, shift=0.0)
Applies a scale and shift to the input tensor.
- anemoi.models.preprocessing.mappings.displace_boundary_atoms(x, lower_atom=None, upper_atom=None, lower_target=None, upper_target=None, eps=0.0)
Displaces exact boundary values to target values (outside of the original range) to give model flexibility to model them as imprecise peaks, instead of delta functions. Reverse transform clamps the imprecise predicted values back to the original range to the original boundary values. Can be used on lower bound, upper bound, or both.
- Parameters:
x (torch.Tensor) – Input tensor
lower_atom (float, optional) – Lower boundary atom
upper_atom (float, optional) – Upper boundary atom
lower_target (float, optional) – Target value for lower boundary atom
upper_target (float, optional) – Target value for upper boundary atom
eps (float, optional) – Epsilon value around the atoms for numerical stability. Default is 0.0.
- anemoi.models.preprocessing.mappings.inverse_displace_boundary_atoms(x, lower_atom=None, upper_atom=None, lower_target=None, upper_target=None, eps=None)
Clamps the values back to the original range, to the original boundary values. Can be used on lower bound, upper bound, or both.
- anemoi.models.preprocessing.mappings.boxcox_converter(x, lambd=0.5, clip_negative=False)
Convert positive var in to boxcox(var) = (x^lambd - 1) / lambd
Special cases: - lambd == 0 -> log(x) - lambd == 1 -> x-1
Notes
Choose lambd < 1 to create a real gap/endpoint basin.
If lambd == 1, this reduces to a bounded smooth transform with no gap.
- anemoi.models.preprocessing.mappings.inverse_boxcox_converter(x, lambd=0.5, clip_negative=None)
Convert back boxcox(var) to var.
- anemoi.models.preprocessing.mappings.power_transform(x, lambd=0.33, clip_negative=False, tangent_linear_above_one=False)
Apply a power transform :param x: Input tensor :type x: torch.Tensor :param lambd: Exponent for the power transform. Default is 0.33. :type lambd: float :param clip_negative: Whether to clip negative values to 0. Default is False. :type clip_negative: bool, optional :param tangent_linear_above_one: Whether to use a tangent-linear extension above 1 instead of the power transform. Useful for max-scaled variables where we still might want to predict values above max without clamping them to max and without blowing them up with the power-transform. Default is False. :type tangent_linear_above_one: bool, optional
- anemoi.models.preprocessing.mappings.inverse_power_transform(x, lambd=0.33, clip_negative=False, tangent_linear_above_one=False)
Inverse power transform with optional inverse tangent-linear branch above 1.
- Parameters:
x (torch.Tensor) – Input tensor
lambd (float) – Exponent for the power transform. Default is 0.33.
clip_negative (bool, optional) – Accepted for symmetry with power_transform but not used in the inverse since the output is already clamped to non-negative values. Default is False.
tangent_linear_above_one (bool, optional) – Whether to use the inverse tangent-linear extension above 1. Default is False.
- anemoi.models.preprocessing.mappings.atanh_converter(x, rho=2.0)
Encode x in [0, 1] to a single scalar value in [-1, 1]
- Mapping:
x == 0 -> -1 0 < x < 1 -> atanh(tanh(rho) * (2x - 1)) / rho x == 1 -> +1
(x == 0.5 -> 0)
- Parameters:
x (torch.Tensor) – Input tensor
rho (float, optional) – Rho parameter for the atanh transform. Default is 0.9. Controls the steepness of the transform at the boundaries.
- anemoi.models.preprocessing.mappings.asinh_converter(x, c=1.0)
Apply an asinh transform
- anemoi.models.preprocessing.mappings.inverse_asinh_converter(x, c=1.0)
Inverse asinh transform
- anemoi.models.preprocessing.mappings.log1p_converter(x)
Convert positive var in to log(1+var).
- anemoi.models.preprocessing.mappings.expm1_converter(x)
Convert back log(1+var) to var.
- anemoi.models.preprocessing.mappings.sqrt_converter(x)
Apply a sqrt transform
- anemoi.models.preprocessing.mappings.inverse_sqrt_converter(x)
Inverse sqrt transform
Imputer
Machine learning models cannot process missing values (NaNs) directly, so missing values in input data and the target must be handled before being handled by the model. The Imputer module in anemoi-models handles missing values (NaNs) before the data is input to the model and after the model’s output is handled by the training loss.
For each input batch, the module identifies NaN locations and replaces the NaNs with a configured imputation value, as specified in the configuration file. If a variable is present in the output data, the imputed values are restored to NaN at the original NaN locations from the first timestep of the input.
The imputer provides the nan mask as a loss scaler
anemoi.training.losses.scalers.loss_weights_mask.NaNMaskScaler to
the loss function, if the scaler is included in
config.training.training_loss. Then the training loss function uses
the nan mask to ignore the imputed values in the loss calculation. This
mask is updated for every batch during training.
During training, diagnostic variables are included in each batch, and
therefore at the input timesteps. Any NaNs in the target data are
weighted by zero to enable proper loss computation. During inference,
however, NaN locations for diagnostic variables are not available (those
fields aren not part of the model input) so the imputer cannot
reintroduces NaNs into the diagnostic output. To insert NaNs into
diagnostic variables, the postprocessor
anemoi.models.preprocessing.postprocessor.ConditionalNaNPostprocessor
has to be used. This masks diagnostic variable entries by setting them
to NaN wherever the chosen (prognostic) masking variable is NaN.
The dynamic imputers are used to impute NaNs in the input data and do not replace the imputed values with NaNs in the output data. Therefore, the nan mask is not provided as a scaler to the loss function either.
The module contains the following classes:
- class anemoi.models.preprocessing.imputer.BaseImputer(config=None, data_indices: IndexCollection | None = None, statistics: dict | None = None)
Bases:
BasePreprocessor,ABCBase class for Imputers.
- get_nans(x: Tensor) Tensor
Get NaN mask from data
The mask is only saved for the first two dimensions (batch, timestep) and the last two dimensions (grid, variable) For the rest of the dimensions we select the first element since we assume the nan locations do not change along these dimensions. This means for the ensemble dimension: we assume that the NaN locations are the same for all ensemble members.
- Parameters:
x (torch.Tensor) – Input tensor with shape (batch, time, …, grid, variable)
- Returns:
Tensor with NaN locations of shape (batch, time, …, grid)
- Return type:
torch.Tensor
- fill_with_value(x: Tensor, index_x: list[int], nan_locations: Tensor, index_nl: list[int]) Tensor
Fill NaN locations in the input tensor with the specified values.
- Parameters:
x (torch.Tensor) – Input tensor
index (list) – List of indices for the variables to be imputed
nan_locations (torch.Tensor) – Tensor with NaN locations
- Returns:
Tensor where NaN locations are filled with the specified values
- Return type:
torch.Tensor
- class anemoi.models.preprocessing.imputer.InputImputer(config=None, data_indices: IndexCollection | None = None, statistics: dict | None = None)
Bases:
BaseImputerImputes missing values using the statistics supplied.
Expects the config to have keys corresponding to available statistics and values as lists of variables to impute.: ``` default: “none” mean:
y
- maximum:
x
- minimum:
q
- class anemoi.models.preprocessing.imputer.ConstantImputer(config=None, data_indices: IndexCollection | None = None, statistics: dict | None = None)
Bases:
BaseImputerImputes missing values using the constant value.
Expects the config to have keys corresponding to available statistics and values as lists of variables to impute.: ``` default: “none” 1:
y
- 5.0:
x
- 3.14:
q
- class anemoi.models.preprocessing.imputer.CopyImputer(config=None, data_indices: IndexCollection | None = None, statistics: dict | None = None)
Bases:
BaseImputerImputes missing values copying them from another variable. ``` default: “none” variable_to_copy:
variable_missing_1
variable_missing_2
- fill_with_value(x: Tensor, index_x: list[int], nan_locations: Tensor, index_nl: list[int]) Tensor
Fill NaN locations in the input tensor with the specified values.
- Parameters:
x (torch.Tensor) – Input tensor
index (list) – List of indices for the variables to be imputed
nan_locations (torch.Tensor) – Tensor with NaN locations
- Returns:
Tensor where NaN locations are filled with the specified values
- Return type:
torch.Tensor